Medium - AI(Spotifys)
in Trend
Trend 파악을 Medium 기고문 요약 포스팅 - 스포티파이 개인추천에 대한 설명
2000년대 초반 Songza에서 처음으로 수동적인 방식으로 사용자에게 재생목록을 제공했다.
여기서 말하는 수동적인 방식은 “음악전문가”팀이 그들이 생각하기에 좋은 음악을 추천했던 것이다.
이 방식은 큐레이터의 취향에 기반을 두기 때문에 사용자 개개인의 모든 취향을 만족 시킬 수 없었다.
MIT Media 연구실에서 The Echo Nest가 탄생했다. 이 알고리즘은 오디오와 노래의 텍스트를 분석하여
각 음악의 특성을 규정짓고 유저에게 추천해 줄 수 있었다.
스포티파이의 Discover Weekly가 세상 살면서 나에게 음악을 추천해준 그 누구보다 좋았다.
이렇게 강력한 Spotify의 음악추천은 어떻게 동작하는 것일까?
Spotify는 위에서 언급한 3가지 모델을 복합적으로 활용한다.
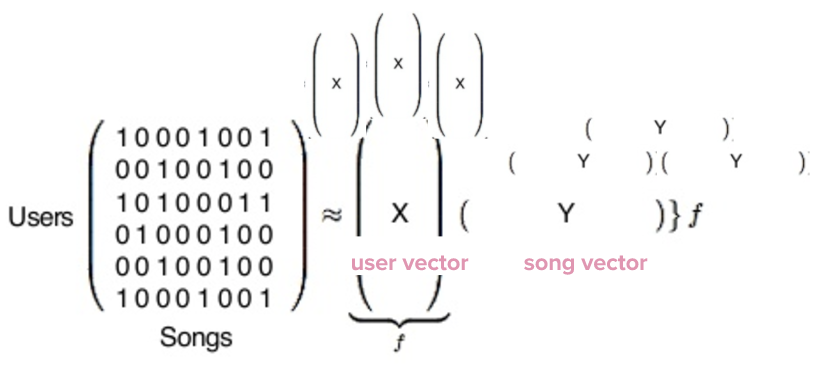
공통 필터 모델 - last.fm에서 최초로 씀

Python을 이용하여 140M의 유저와 30M의 노래들을 행렬계산하여 각 벡터값을 뽑아낸다.
이 값 자체는 의미가 없지만 비교를 함으로써 매우 유용하게 쓰인다.
자연어 처리 모델

자연어 처리 엔진은 인간의 언어를 컴퓨터가 분석하고 이 과정에서 특정 구문의 가중치를 달리 두어 점수를 산정하는 것이다.
이러한 자연어 처리에 대한 깊은 논의는 이 포스트의 주제에 맞지 않으므로 상위레벨에서 간략히 설명하자면
Spotify는 블로그나 음악에 관련된 기사를 크롤링하여 사람들이 특정 노래에 대해 어떻게 생각하는지 정보를 생산한다.
Spotify가 수집된 데이터를 바탕으로 정확히 어떤 절차를 거치는 지는 명확하지 않지만 Top term을 추출하여
활용하는 것 같다.
raw Audio 분석모델

이 모델은 위의 두 모델과는 달리 사용자에게 새로운 노래를 추천해 주기 위한 목적이 크다.
유명하지 않은 노래는 공통 필터 모델과 자연어 처리 모델 모두에서 주목받지 않기 때문에 사용자에게
잘 추천되지 않을 것이다. 이러한 문제를 해결하기 위해 Raw Audio 분석 모델을 쓰는 것이다.
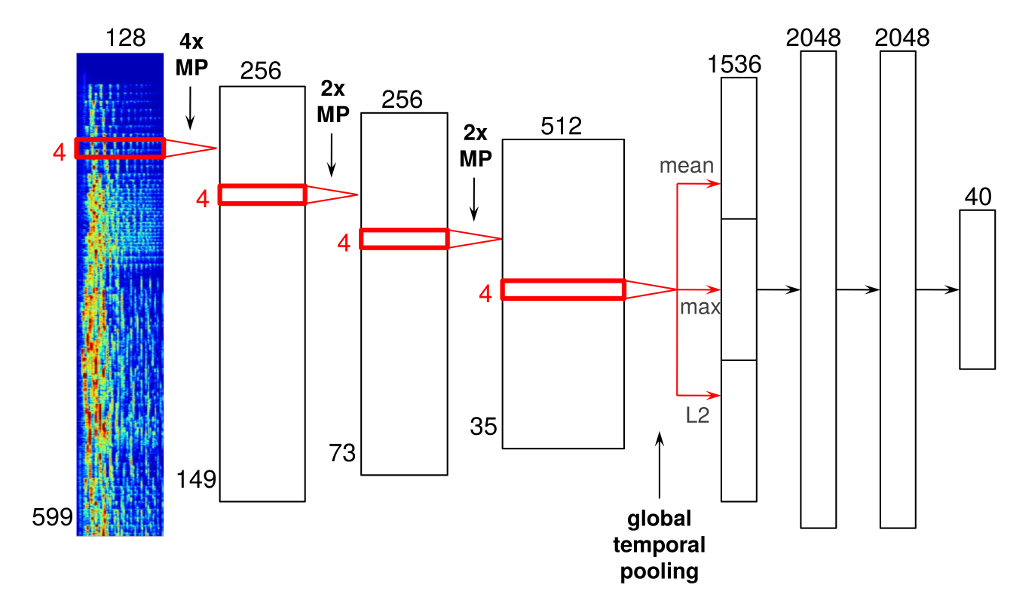
Spotify에서는 신경 네트워크 구조를 이용하여 분석을 한다.
4개의 나선형 레이어를 통하면 하나의 음악에 대해 시간특성, key, mode, 빠르기 등이 구분되며
이를 활용하여 유사한 음악을 사용자에게 추천해주는 것이다.
Summary
- Spotify의 효과적인 추천방식은 크게 3가지 모델을 사용한다.
- Spotify의 방대한 저장공간, Hadoop Cluster 등 방대한 데이터를 바탕으로 가능했다.
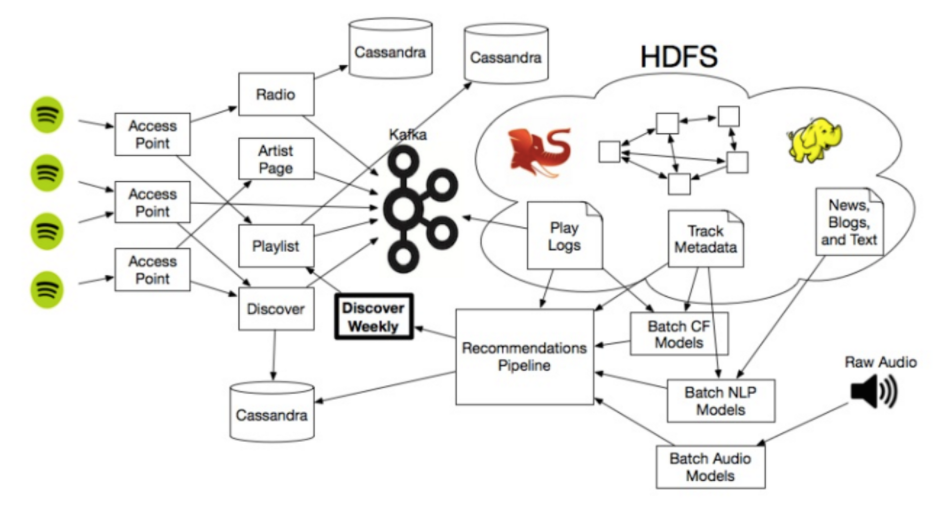 Spotify recommendation pipeline
Spotify recommendation pipeline