Medium - Natural Language Processing is Fun!
in Trend
Trend 파악을 Medium 기고문 요약 포스팅 - 자연어 처리 과정은 즐겁습니다!, 컴퓨터가 사람의 언어를 이해하는 방법에 대하여.
 불행하게도 우리는 모든 데이터가 구조화된 세상에서 살고 있지 않습니다.
불행하게도 우리는 모든 데이터가 구조화된 세상에서 살고 있지 않습니다.
컴퓨터는 스프레드 시트나 데이터 베이스 테이블과 같이 구조화된 데이터를 이용해 작업을 하는데 뛰어납니다. 그러나 사람이 의사소통에 사용하는 단어들은 테이블에 있는 것이 아니죠. 그것은 컴퓨터에게는 부적절 합니다.
영어의 단어나 다른 나라의 언어들처럼 세상의 많은 정보들은 비구조적입니다. 어떻게 해야 우리는 컴퓨터가 비구조적 텍스트를 이해하고 데이터를 추출하도록 할 수 있을까요?

NLP, 자연어 처리는 컴퓨터가 사람의 언어를 이해시키도록 하는 것에 초점을 맞춘 AI 분야의 하위항목입니다. NLP가 어떻게 동작하는 지 확인하고 파이썬으로 데이터를 추출할 수 있는 프로그램을 작성하는 법에 대해 배워봅시다!
Can Computers Understand Language?
컴퓨터가 있어온 이래로 프로그래머들은 영어와 같은 언어를 이해하는 프로그램을 작성하기 위해 많은 시도를 해왔습니다. 이유는 꽤 명백하죠, 인류는 수천년간 내려오는 방대한 기록물이 있고 컴퓨터가 그것을 읽고 모든 것을 이해한다면 매우 도움이 될 것이기 때문입니다.
아직 컴퓨터는 인간처럼 영어를 이해할 수 없습니다. 그러나 할 수 있는 것들은 이미 많이 있습니다. 특정 제한된 영역에서는 당신이 NLP를 이용해 할 수 있는 것은 마법처럼 보일 것입니다. 당신의 프로젝트에 NLP를 적용한다면 많은 시간을 절약할 수도 있겠죠.
나아가 최근 NLP의 진보는 파이썬 오픈소스 라이브러리로 쉽게 접근 가능합니다.
단 몇줄의 파이썬 코드로 놀라운 일들을 할 수 있죠.
Extracting Meaning from Text is Hard
영어를 읽고 이해하는 처리과정은 매우 복잡합니다. 심지어 영어의 비규칙성과 비논리적인 것을 고려하지 않더라도 말이죠. 예를 들어 이 뉴스 헤드라인이 의미하는 것은 무엇일까요?
“Environmental regulators grill business owner over illegal coal fires”
환경 규제측은 탄소 배출량을 초과한 사업주를 다그쳤다 일까요 아니면 문자 그대로 환경 규제측이 사업주들을 구워 버렸을까요? 보다시피 영어를 컴퓨터로 분석하는 것은 복잡합니다.
머신러닝에서 복잡한 것을 한다는 것은 파이프라인을 구축하는 것을 의미합니다. 이러한 접근은 문제를 작은 조각으로 쪼개고 각 조각을 머신러닝을 사용해서 해결하는 것입니다. 그리고 여러 개의 머신러닝 모델을 묶는 것으로 당신은 복잡한 일들을 처리할 수 있습니다.
이것이 우리가 NLP를 사용할 전략입니다. 영어를 이해하는 과정을 작은 덩어리로 쪼개고 각 조각을 어떻게 처리하는지 확인해 봅시다.
Building an NLP Pipeline, Step-by-Step
위키피디아의 글을 잠깐 보도록 하죠.
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
Source: Wikipedia article “London”
이 문단은 몇몇 유용한 사실을 담고 있습니다. 컴퓨터가 이것을 읽고 런던이 도시이며 영국에 있고 로마인들이 정착했다는 것을 이해하면 정말 좋을 것입니다. 그러나 거기까지 가기위해 우리는 쓰여진 언어의 기본 원리를 컴퓨터에게 학습시켜야 합니다.
Step 1: Sentence Segmentation
파이프라인의 첫 번째 과정은 텍스트를 문장으로 쪼개는 것입니다. 이렇게 말이죠,
“London is the capital and most populous city of England and the United Kingdom.”
“Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.”
“It was founded by the Romans, who named it Londinium.”
단락 전체를 컴퓨터가 이해하는 것 보다 하나의 문장을 이해하는 프로그램을 짜는 게 훨씬 쉬울 겁니다.
문장을 나누는 모델은 마침표를 이용해 구분을 하면 매우 쉽게 코딩할 수 있습니다. 그러나 최근 NLP 파이프라인은 깔끔하게 규격화 되지 않은 문서를 처리하기 위해 더욱 복잡한 기술을 사용하기도 합니다.
Step 2: Word Tokenization
이제 우리는 문서를 문장으로 구분해 냈고 한 번에 한 문장씩 처리할 것입니다. 첫 번째 문장부터 시작 해봅시다.
“London is the capital and most populous city of England and the United Kingdom.”
우리 파이프라인의 다음단계는 단어나 토큰으로 문장을 쪼개는 것 입니다. 이것을 토큰아이제이션이라 부르며 결과는 이렇게 됩니다.
“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
영어에서 토큰아이제이션은 매우 쉽습니다. 스페이스를 이용해서 분리하면 되거든요. 그리고 마침표 또한 분리된 토큰으로 활용할 것입니다. 마침표도 의미가 있으니까요.
Step 3: Predicting Parts of Speech for Each Tokenization
다음으로 우리는 각 토큰이 동사인지 명사인지 형용사인지 추측하는 것을 시도할 겁니다. 문장의 단어의 규칙을 아는 것은 그 문장이 뭘 말하는지 알아내는데 도움을 줄 것입니다.
우리는 미리 학습된 part-of-speech 규격화 모델을 이용해 여기에 각 단어를 넘겨주는 것으로 이것을 할 수 있습니다.

part-of-speech 모델은 태그가 달린 수 백만개의 영어문장을 통해 학습되었습니다.
위의 모델이 완전히 통계에 근간을 둔다는 것을 생각하면서 - 실제로 사람이 하는 것처럼 단어를 이해하는 것이 아닙니다. 단지 이전의 비슷한 문장을 통해 추측하는 것아죠
작업이 끝나면 결과는 이렇게 됩니다.

이 정보들을 이용해 우리는 이미 조금 씩 기본적인 의미를 수집할 수 있습니다. 예를 들어 우리는 문장이 런던과 수도라는 명사를 포함하고 있다는 것을 볼 수 있고 이것은 아마도 런던에 관한 문장이라는 것을 알 수 있죠.
Step 4: Text Lemmatization
영어에서 단어는 다양한 형태로 나타납니다. 다음의 두 문장을 보시죠:
I had a pony.
I had a two ponies
두 문장은 똑같이 명사 조랑말에 대해 얘기하고 있습니다만 다른 형태를 보이고 있죠. 컴퓨터로 텍스트를 다룰 때에는 각 단어의 기본 형을 아는 것이 매우 도움이 됩니다. 그래야 같은 문장이 동일한 개념을 말하는 것이라는 걸 캐치할 수 있거든요. 그렇지 않으면 pony와 ponies를 컴퓨터는 다른 것이라고 인식할 겁니다.
NLP에서 우리는 이것을 찾는 것을 기본형 정리라고 합니다. 문장의 각 단어의 기본형을 알아내는 것이죠.
동사에도 똑같이 적용합니다. had를 동사원형인 have로 정리하는 것이죠. 기본형 정리는 일반적으로 기본형 테이블을 찾아보는 것으로 수행됩니다.
이것이 동사원형을 기본형 정리에 추가한 뒤 결과 값입니다.

is 가 be로 바뀐 것을 확인 하실 수 있을 겁니다.
Step 5: Identifying Stop Words
다음으로 우리는 문장에서 각 단어의 중요성을 판단할 것입니다. 영어는 and와 the 같은 관사가 매우 많이 나타납니다. 문장을 통계를 내려고 한다면 이러한 관사의 빈도가 매우 높게 나타나기 때문에 노이즈처럼 작용합니다. 어떤 NLP 파이프라인은 그들을 stop words로 취급합니다. 그것은 통계를 낼 때 제외하고 싶은 단어들로 설정하는 것이죠.
stop words들을 음영처리한 결과를 봅시다.

stop word는 보통 해당 단어들의 리스트를 나열한 것을 통해 구분합니다. 그러나 모든 응용프로그램에 적합한 stop word 리스트의 기준은 없습니다. 당신의 응용프로그램이 무시하고 싶은 단어에 따라 달라집니다.
만약 당신이 락밴드 검색엔진을 구축하려고 한다면 The를 stop word로 지정하면 안될겁니다. 왜냐하면 1980년대 유명한 The The 밴드가 있으니까요!
Step 6: Dependency Parsing
다음 단계는 문장 속의 모든 단어들이 얼마나 연관있는지 알아내는 것입니다. 이것을 의존도 분석이라고 합니다.
이것의 목적은 문장 속의 단어들을 모두 하나의 부모를 가진 트리로 구성하는 것입니다. 트리의 루트는 문장의 메인 동사가 될 것입니다. 문장을 트리로 파싱한 첫 번째 모습입니다.
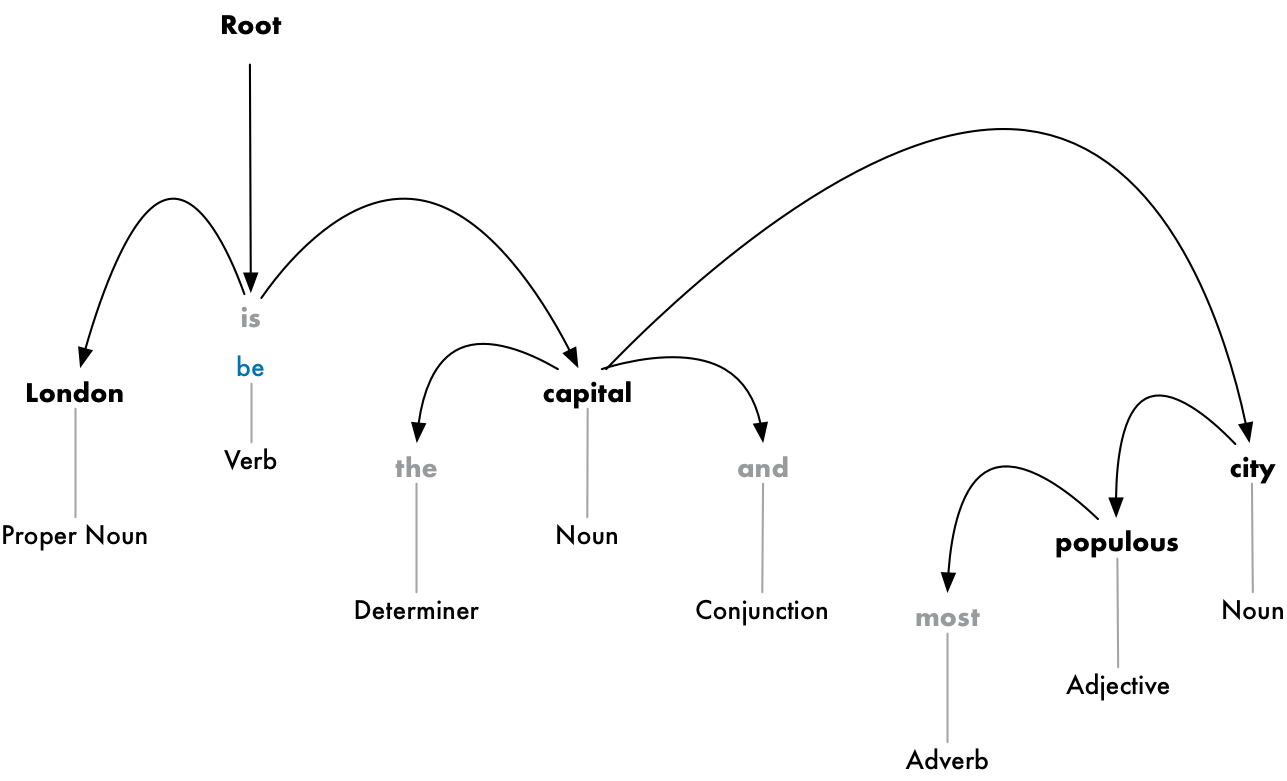
그러나 여기서 우리는 더 나아갈 겁니다. 각 단어의 부모들을 구분하는 것을 추가해서 두 단어 사이에 존재하는 관계를 예측할 수 있습니다.
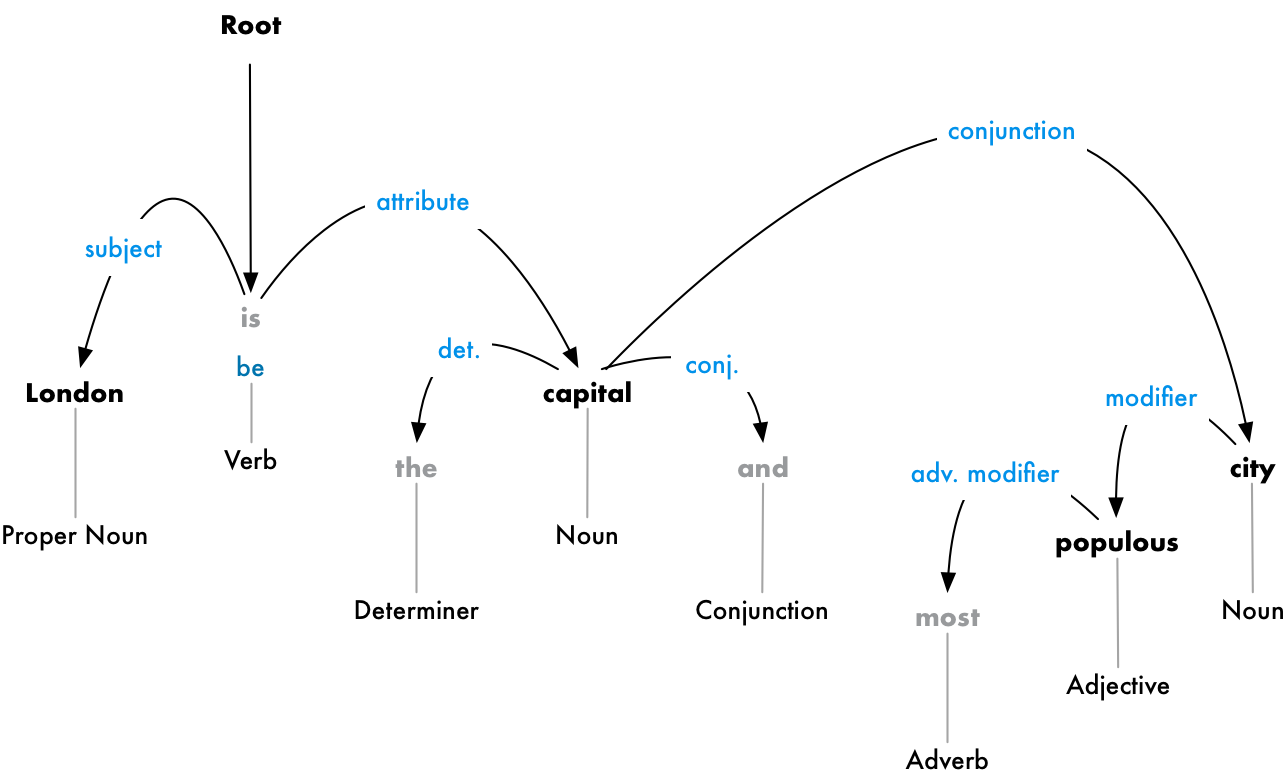
이 파싱트리는 문장의 주제가 명사 런던이 동사 be와 수도라는 관계를 가지고 있다는 것을 보여줍니다. 우리는 마침내 유용한 정보를 얻었습니다. 런던은 수도입니다! 그리고 우리가 모든 문장에 파싱트리를 만든다면 우리는 런던이 영국의 수도라는 것을 알게 될겁니다.
우리가 머신러닝 모델을 사용하여 part-of-speech 를 예측한 것처럼 의존도 분석도 머신러닝모델에 단어들을 넘겨줌으로써 얻어지는 결과입니다. 그러나 의존도 분석은 꽤나 복잡한 작업이고 자세하게 설명하기 위해선 이 지면의 모든 공간을 차지할 겁니다. 어떻게 동작하는 지 정확히 알고 싶다면 Matthew Honnibal의 훌륭한 “Parsing English in 500 Lines of Python”을 참고하세요!
그러나 2015년에 저자가 강조한 사항에도 불구하고 이러한 접근은 이제 표준이 되었습니다. 사실 도태된 것이고 저자도 더 이상 사용하지 않죠. 2016년에 구글이 Parsey McParseface라는 새로운 의존도 분석기를 릴리즈 했습니다. 산업 전반에 빠르게 퍼진 딥러닝 접근법을 사용한 것이었죠. 그러고 몇 년후 ParseySaurus라는 개선된 버전이 나왔습니다. 달리 말하자면 파싱 기술 영역은 활발히 연구가 이뤄지고 끈임없이 개선이 되는 분야라는 것이죠.
그리고 많은 영어 문장들은 모호하고 그냥 파싱하기 어렵다는 것을 기억해야 합니다. 그런 경우 이전에 파싱된 버전에 의해서 추측을 하겠지만 잘못된 결과가 될 수도 있죠. 그러나 시간이 지날수록 NLP 모델은 텍스트를 분석하기 위해 발전을 거듭할 겁니다.
Step 6b: Finding Noun Phrases
여기까지 우리는 문장을 분리된 요소로서 취급했습니다. 그러나 때때로 단어들을 그룹짓는게 더욱 말이 되는 경우가 있습니다. 우리는 의존성 분석 트리를 이용해 자동적으로 같은 의미를 말하는 단어들을 한데 묶을 수 있습니다.
예를 들자면 이것 대신에

이렇게 명사 구문을 그룹지을 수 있는 것이죠

이 단계를 수행할지 말지는 우리의 최종 목적에 달려있습니다. 그러나 이것은 문장을 빠르고 쉽게 단순화 시키는 것입니다.
Step 7: Named Entity Recognition (NER)
이제 어려운 작업은 모두 끝났습니다. 이제 초등학교 문법시간은 뒤로하고 실질적인 의미를 추출해 봅시다.
우리의 문장에서는 다음과 같은 명사들이 있었습니다.

이 명사들 중 일부는 실제로 존재하는 것들입니다. 예를 들어 런던과 영국, 대영제국은 지도에 실제적으로 존재하는 장소죠. 이것을 탐지하는 것이 가능하다면 멋질겁니다! 이 정보를 이용한다면 우리는 아마 NLP를 이용하여 문서에 언급된 실제 장소를 자동적으로 추출하도록 할 수도 있죠.
Named Entity Recognition 통칭 NER의 목적은 실존하는 명사들을 탐지하고 그것이 의미하는 바를 라벨링하는 것입니다. NER 태깅을 작업을 수행한 후 우리의 문장은 이렇게 표현됩니다.

그러나 NER 시스템은 단지 단순한 사전을 찾아보는 작업이 아닙니다. 대신에 명사의 단어가 의미하는 바가 무엇인지 통계와 문맥을 활용하여 추측하는 것입니다. 좋은 NER시스템은 Brookyln Decker는 사람이고 Brooklyn은 장소라는 것을 문맥적 흐름을 통해 구분할 수 있어야 합니다.
다음은 NER 시스템을 통해 태그를 붙일 수 있는 객체들의 종류입니다.
- 사람이름
- 회사 이름
- 지리학적 장소
- 제품명
- 날짜와 시간
- 돈의 액수
- 행사의 이름
NER은 텍스트에서 구조화된 정보를 손쉽게 뽑아낼 수 있기 때문에 수도없이 쓰입니다. 이것이 NLP 파이프라인에서 가치를 도출하는 가장 쉽고 빠른 방법입니다.
Step 8: Coreference Resolution
이 시점에서 우리는 이미 문장 속에서 유용한 묘사를 가지고 있습니다. 우리는 각 단어들이 서로 어떤 관계이고 어떤 요소를 말하는지 알고 있죠
그러나 우리는 아직 큰 문제가 있습니다. 영어는 대명사들로 가득합니다. 그나 그녀 그것 처럼 말이죠. 사람들은 문맥을 기준으로 이 단어들이 의미하는 바를 알아냅니다. 그러나 우리의 NLP 모델은 대명사가 무엇인지 모릅니다 왜냐하면 한번에 한 문장만 확인하기 때문이죠.
예를 들어봅시다.
<i“It was founded by the Romans, who named it Londinium.”i>
현재 NLP 파이프 라인은 그것이 로마인들에 의해 세워졌다 라고 할 것입니다. 그러나 런던은 로마인들에 의해 세워졌다 라고 하는 것이 훨씬 유용할 것입니다.
사람으로서 이 문장을 읽는다면 당신은 쉽게 그것이 런던이라는 것을 알 수 있습니다. 동일지시성 해결은 문장들 사이의 대명사들을 매핑하는 것입니다. 다음은 런던이라는 단어에 대해 동일지시성 해결을 수행한 결과입니다.

동일 지시성 정보를 파싱 트리와 NER 태그 정보 등과 함께 활용한다면 우리는 이 문서에서 많은 정보를 추출할 수 있을 것입니다.
동일지시성 해결은 우리의 파이프라인에서 가장 구현하기 어려운 부분입니다. 문장 파싱보다 훨씬 어려운 부분이죠. 최근 딥러닝 방식으로 접근한 것은 훨씬 정확도가 높긴 하지만 아직도 완벽하진 않습니다. 만약 당신이 어떻게 동작하는 지 확인하고 싶다면 여기를 확인하세요.
Coding the NLP Pipeline in Python
다음은 완전한 NLP 파이프라인의 모습입니다.

후.. 엄청나게 많은 스텝이네요. 자 그럼 우리가 이것을 어떻게 코딩해야 할까요? spaCy와 같이 놀라운 파이썬 라이브러리 덕분에 이미 완료되었습니다. 당신은 그저 사용하기만 하면 되죠.
Extracting Facts
spaCy를 이용해서 할 수 있는 것은 놀랍습니다. 그러나 spaCy의 결과물을 좀 더 복잡한 데이터 추출 알고리즘에 넣을 수 있습니다. textacy라는 파이썬 라이브러리는 일반적인 데이터 추출 알고리즘들이 구현되어 있습니다.
아래는 런던 위키피디아를 분석한 결과 입니다.
Here are the things I know about London:
- the capital and most populous city of England and the United Kingdom
- a major settlement for two millennia
- the world's most populous city from around 1831 to 1925
- beyond all comparison the largest town in England
- still very compact
- the world's largest city from about 1831 to 1925
- the seat of the Government of the United Kingdom
- vulnerable to flooding
- "one of the World's Greenest Cities" with more than 40 percent green space or open water
- the most populous city and metropolitan area of the European Union and the second most populous in Europe
- the 19th largest city and the 18th largest metropolitan region in the world
- Christian, and has a large number of churches, particularly in the City of London
- also home to sizeable Muslim, Hindu, Sikh, and Jewish communities
- also home to 42 Hindu temples
- the world's most expensive office market for the last three years according to world property journal (2015) report
- one of the pre-eminent financial centres of the world as the most important location for international finance
- the world top city destination as ranked by TripAdvisor users
- a major international air transport hub with the busiest city airspace in the world
- the centre of the National Rail network, with 70 percent of rail journeys starting or ending in London
- a major global centre of higher education teaching and research and has the largest concentration of higher education institutes in Europe
- home to designers Vivienne Westwood, Galliano, Stella McCartney, Manolo Blahnik, and Jimmy Choo, among others
- the setting for many works of literature
- a major centre for television production, with studios including BBC Television Centre, The Fountain Studios and The London Studios
- also a centre for urban music
- the "greenest city" in Europe with 35,000 acres of public parks, woodlands and gardens
- not the capital of England, as England does not have its own government
자동적으로 수집된 정보의 양이 꽤나 놀랍군요.
What else can we do?
spaCy와 textacy의 문서를 살펴보면 많은 예제들과 텍스트 분석을 통해 할 수 있는 일들이 나와있습니다. 우리가 본 것은 아주 작은 예제에 불과하죠.
구글에서 검색어를 입력하면 연관된 단어가 나오는 것도 구현해 볼 수 있습니다.
Summary
- NLP 파이프라인을 통해 문장을 컴퓨터가 학습하는 방법을 배웠다.
- 중간 중간 파이프라인에 쓰이는 모델들은 정확도를 올리기 위해 지금도 활발한 연구가 이루어지고 있다.
- 파이썬 라이브러리에 파이프라인이 이미 구현되어 있으므로 손쉽게 NLP를 통한 응용프로그램을 만들 수 있다.