Medium - Kubernetes 101; Pods, Nodes, Containers, and Clusters
in Trend
Trend 파악을 Medium 기고문 요약 포스팅 - Kubernetes : 저장소, 노드, 컨테이너, 클래스
쿠버네티스는 클라우드 환경에서 소프트웨어를 배포하고 관리하는 새로운 기준으로 빠르게 자리잡고 있습니다. 그러나 쿠버네티스는 강력한 능력은 배우는데 조금 힘듭니다. 처음 접하는 사람에게는 공식 문서를 읽는 것도 벅찰 수가 있습니다. 시스템을 구축하는 부분이 매우 많기 때문에 여러분의 유즈케이스와 연관되는 것을 구분하는 게 힘들 수도 있습니다. 이 블로그 포스트는 쿠버네티스를 단순화하여 설명해 드릴 것이지만 가장 중요한 컴포넌트들이 어떻게 구성되어 있는지 상위 레벨의 관점으로 파악하실 수 있도록 해볼겁니다.
자 그럼 먼저 하드웨어가 어떻게 표현되는지 살펴보겠습니다.
Hardware
Nodes

노드는 쿠버네티스의 가장 작은 단위의 컴퓨팅 하드웨어 입니다. 당신의 클러스터에 단일 머신을 대표하죠. 많은 생산 시스템에서 노드는 데이터센터의 실제 머신이거나 구글 클라우드 플랫폼 같은 곳에서 호스팅하는 가상 머신에 해당합니다. 그러나 관습에 너무 빠지진 마세요. 이론적으로는 거의 모든 것으로 노드를 만들 수 있습니다.
노드를 머신으로 생각하는 것은 우리에게 추상화 층을 추가할 수 있도록 해줍니다. 이제 기기의 개별적인 특성에 대한 것은 잊어버리고 우리는 단순히 머신을 CPU와 RAM 자원으로 구성된 자원으로 볼 것입니다. 이와 같은 방식에서는 특정 머신은 쿠버네티스 클러스 내의 어떠한 머신으로도 대체될 수 있습니다.
The Cluster

개별적인 노드들도 유용하겠지만 그것은 쿠버네티스의 방식이 아닙니다. 일반적으로 노드들의 개별 상태에 대해서 걱정하는 것 대신에 클러스터를 하나의 전체로 생각하셔야 합니다.
쿠버네티스에서 더욱 성능좋은 머신을 만들기 위에 노드의 자원을 한데 모아 노드풀로 만듭니다. 클러스터상에 프로그램을 배포한다면 똑똑하게 개별노드로 분산처리하여 작업을 할 것입니다. 만약 노드가 추가되거나 삭제될 경우 클러스터는 작업을 다른 필요한 곳으로 옮길 것입니다. 그렇다해도 개별적인 머신들이 실제로 코드를 수행하는데 있어서 개발자나 프로그램에게는 아무런 영향이 없을 것입니다.
만약 이런 벌집모양 시스템이 스타트렉의 보그를 생각나게 한다면 당신만 그런 것이 아닙니다. 사실 보그는 쿠버네티스의 전신은 구글 내부 프로젝트의 이름입니다.
Persistent Volumes
클러스터에서 동작하는 프로그램이 어떤 특정 노드에서 동작하는지 확신할 수 없기 때문에 저장되는 데이터 또한 임의의 장소에 저장될 수가 없습니다. 만약 프로그램이 파일에 데이터를 나중에 저장하려고 시도하고 새로운 노드에서 다시 실행되는 경우 파일에 저장하려고 했던 데이터는 이미 없어졌을 겁니다. 이런 이유 때문에 각 노드에 연결된 전통적인 로컬 저장소는 프로그램을 붙잡아 두기 위한 일시적인 캐시처럼 취급되고 데이터가 지역적으로 영구히 저장되는 것은 기대할 수 없습니다.

데이터를 영구히 저장하기 위해서 쿠버네티스는 Persistent Volumes를 사용합니다. 모든 노드의 CPU와 RAM 자원들이 클러스터에 의해 효과적으로 풀링되고 관리되지만 영구 파일 저장소는 그렇지 않습니다. 대신에 로컬이나 클라우드 드라이브는 클러스터에 Persistent Volume으로서 연결됩니다. 이 것을 클러스터에 외장 하드를 연결한다고 생각하셔도 됩니다. Persistent Volume은 특정 노트에 연관되지 않고 클러스터에 마운트 될수 있는 파일 시스템을 제공합니다.
Software
Containers

쿠버네티스에서 동작하는 프로그램들은 리눅스 컨테이너로 포장됩니다. 컨테이너는 표준으로 넓게 자리잡았기 때문에 쿠버네티스에서 배포할 수 있는 많은 프리셋 이미지들이 있습니다.
컨테이너화를 통해 여러분은 독립된 리눅스 실행환경을 만들 수 있습니다. 특정 프로그램과 모든 의존성들은 하나의 파일에 묶음으로 처리되어 인터넷에 공유될 것입니다. 아주 작은 설정만하면 누구나 컨테이너를 다운받아서 그들의 인프라를 배포할 수 있는 것이죠. 컨테이너를 만드는 것은 강력한 CI&CD 파이프라인 형태로 프로그래밍을 통해 할 수 있습니다.
여러개의 프로그램들이 하나의 컨테이너에 추가될 수 있지만 가능하다면 하나의 컨테이너에 하나의 프로그램으로 제한하는 것이 좋습니다. 작은 컨테이너 여러 개가 큰 큰테이너 하나보다 낫습니다. 각 컨테이너들이 하나의 프로그램에만 집중해야 업데이트, 배포, 그리고 이슈를 해결하는 것이 쉬울겁니다.
Pods

여러분이 과거에 쓰셨던 다른 시스템과 달리 쿠버네티스는 컨테이너를 바로 실행하지 않고 팟이라고 불리는 상위레벨 구조로 1개 이상의 컨테이너를 래핑합니다. 같은 팟에 있는 컨테이너 들은 동일한 자원과 로컬 네트워크를 공유합니다. 컨테이너들은 같은 팟에 있는 다른 컨테이너들과 독립된 상태를 유지하면서 동일한 머신에 있는 것처럼 쉽게 통신할 수 있습니다.
팟들은 쿠버네티스의 복사 단위로 사용됩니다. 만약 당신의 응용프로그램이 너무 유명해서 단일 팟 인스턴스로 커버가 안되는 경우 쿠버네티스는 클러스터에 새로운 팟을 복사하여 배포하도록 설정할 수 있습니다. 과부하가 아니더라도 로드 밸런싱과 실패 저항을 위해 여러 개의 팟을 복사해서 갖고 있는 것이 일반적입니다.
팟은 여러개의 컨테이너를 가질 수 있지만 가능하다면 제한을 걸어야 합니다. 왜냐하면 팟은 유닛으로 확장되거나 축소되는데 팟에 있는 모든 컨테이너들이 같이 확장되므로 개별적인 필요성을 고려할 수 없습니다. 따라서 이것은 자원을 낭비하게되고 비싼 요금이 나오게 되죠. 이것을 해결하기 위해 팟은 최대한 작게 남겨놓아야 합니다. 일반적으로 하나의 매인 프로세스와 두어개의 헬퍼 컨테이너들을 담습니다.(헬퍼 컨테이너들은 side-cars라고 불립니다.)
Deployments
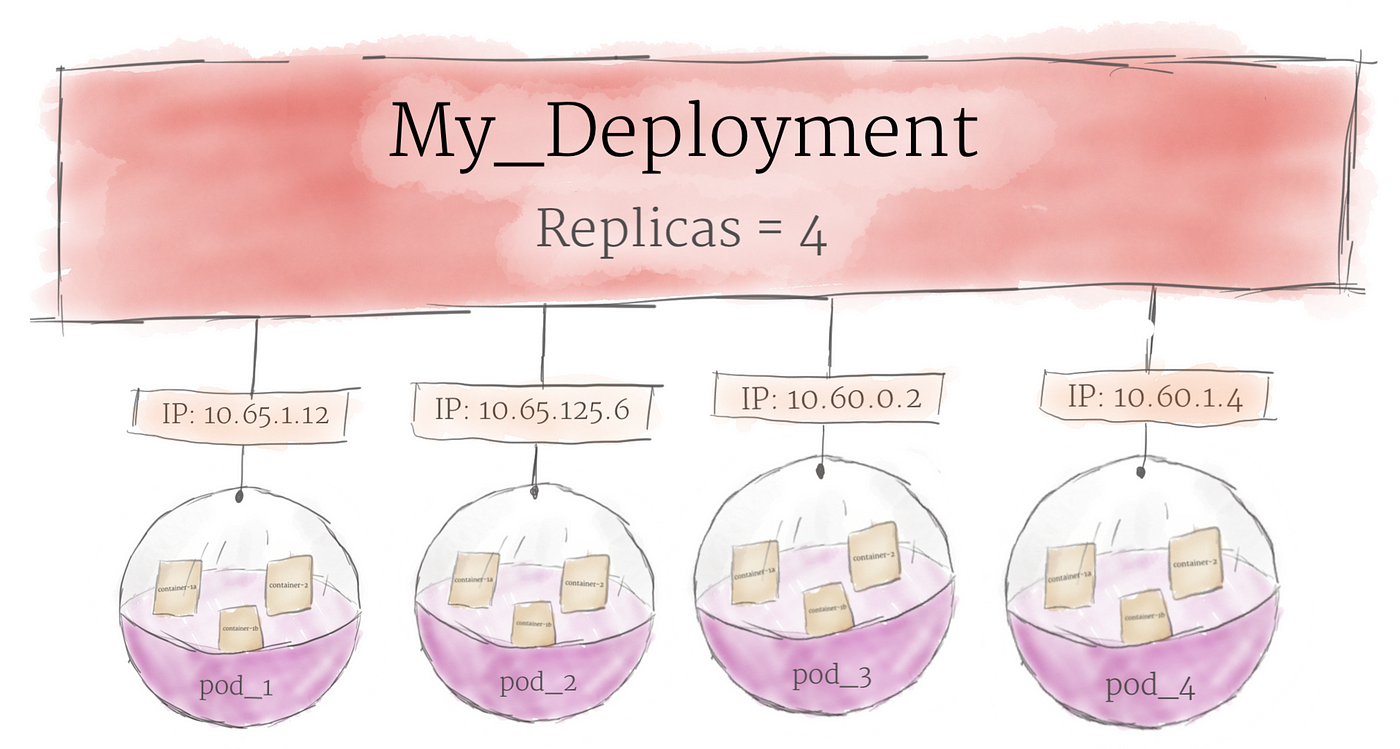
팟들은 쿠버네티스에서 연산의 기본 단위이지만 클러스터에서 직접적으로 실행되지는 않습니다. 대신에 팟들은 deployment라는 추상화 계층에 의해 주로 관리됩니다.
deployment의 주 목적은 한번에 몇 개의 복제된 팟들이 실행될 것인지 선언하는 것입니다. deployment가 클러스터에 추가되면 그것은 자동적으로 요청된 팟의 수만큼 스핀업하고 팟들을 감시합니다. 만약 팟이 죽으면 자동적으로 다시 만들죠.
deployment를 사용하는 것은 팟들을 수동적으로 다룰필요가 없다는 것입니다. 시스템에 대한 이상적인 상태를 선언하기만 하면 자동적으로 관리된다는 것이죠.
Ingress

위에서 설명드린 개념을 이용해서 여러분은 클러스터의 노드를 만들고 pod의 deployments를 클러스터에서 실행시킬 수 있을겁니다. 그러나 마지막으로 해결해야 될 문제가 남았습니다. 외부 트래픽을 허용하는 것입니다.
기본적으로 쿠버네티스는 외부와 독립된 팟을 제공합니다. 팟에서 동작하는 서비스와 통신하기 위해서는 통신 채널을 열어야 합니다. 이것을 ingress라고 합니다.
ingress를 클러스터에 추가하는 방법은 여러가지가 있습니다. 가장 일반적인 방식은 Ingress 컨트롤러를 이용하거나 LoadBalancer를 이용하는 것입니다. 두 옵션에 대한 비교는 이 포스트의 범위를 넘어서기 때문에 여기서는 넘어가지만 ingress는 쿠버네티스로 테스트하기전에 꼭 처리해야하는 것이라는 것을 명심하세요!
Summary
- 쿠버네티스의 개념과 하드웨어/소프트웨어 구조적 개요 파악
- 쿠버네티스를 통한 클라우드 배포의 장점