Medium - Query data from S3 files using Amazon Athena
in Trend
Trend 파악을 위한 Medium 기고문 포스팅 - 아마존 아테나를 이용해서 S3 파일에 쿼리 사용하기
아마존 아테나는 인터렉티브 쿼리 서비스로 아마존의 심플 저장 서비스 (S3)의 데이터를 SQL을 사용해서 쉽게 분석할 수 있게 해주는 것입니다. 그래서 S3에 저장된 방대한 데이터를 위한 또다른 쿼리 엔진이라고 보시면 될 것 같습니다. 아테나는 아파치 드릴과 같이 다른 SQL 쿼리 엔진과 매우 비슷합니다. 아파치 드릴과 다른 점이라면 아테나는 오직 아마존 자체 S3에서만 사용가능 하다는 것입니다. 그러나 아테나는 CSV, Parquet, JSON과 같이 다양한 파일포맷에 쿼리를 날릴 수 있죠.

이 기사에서는 S3에 저장된 간단한 .csv 데이터를 이용해서 아테나의 테이블을 설정하는 방법을 알아볼 것입니다. 그 전에 샘플 CSV 파일이 필요합니다. 파일을 다운로드 하신뒤에 저장소를 만들어 봅시다. 저는 아테나를 테스트 해볼 수 있는 독립적인 저장소를 만드는 것을 추천드립니다만 그냥 존재하는 저장소를 사용하셔도 무방합니다. 그럼 이제 S3에 파일이 있으실 테니 아테나를 켭시다. 아테나 홈페이지에서 테이블을 만드는 옵션을 볼 수 있습니다. 제 것은 아래의 스크린 샷과 같은데 그건 이미 테이블이 좀 있기 때문입니다. 스크린 샷에서 보실 수 있겠지만 테이블을 만들 때 여러가지 옵션을 선택할 수 있습니다. 이 기사에서는 기본적인 것만 살펴볼 것이기 때문에 “Create table from S3 bucket data”를 선택하세요.

한번 옵션을 선택하면 그 다음에는 4단계의 절차에 따라서 테이블을 만들게 됩니다. 이 스텝들을 간략히 살펴보시죠.
Step 1: Name & Location
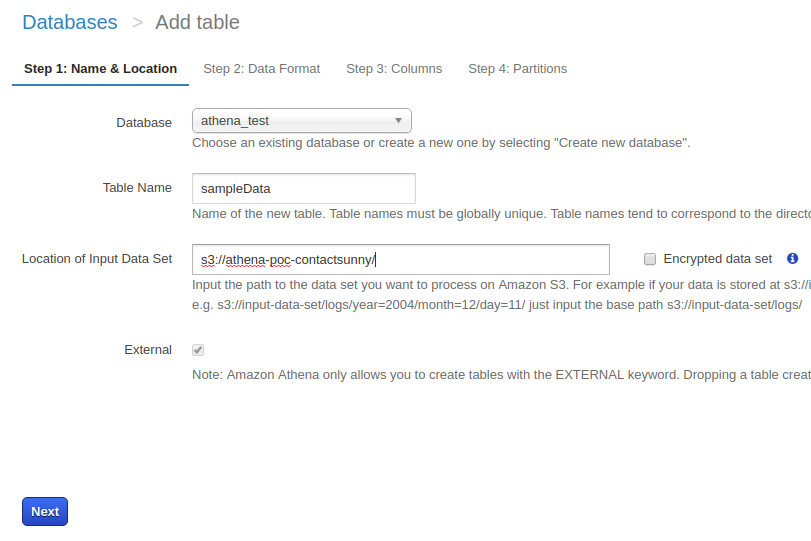
위의 스크린샷에서 볼 수 있듯이 이 단계에서는 데이터베이스와 테이블 이름, 그리고 테이블이 사용하게될 데이터가 있는 S3 폴더를 정의합니다. 만약 데이터베이스가 있다면 드롭다운에서 선택할 수 있습니다. 그렇지 않다면 오른쪽 화면에서 데이터베이스를 만드는 옵션을 선택할 수 있습니다. 그다음은 테이블의 이름을 입력합니다. 예를 들어서 저는 테이블의 이름을 sampleData라고 했습니다.
그다음은 S3에 파일이 저장되어 있는 폴더의 경로를 전달합니다. 기억하셔야 할 것은 파일의 경로를 전달하는 것이 아니라 폴더의 경로를 전달하는 것입니다. 따라서 폴더에 있는 모든 일치하는 파일 포맷들이 데이터 소스로 쓰이게 됩니다. 여기서 암호화 옵션은 생략하겠습니다. 주목하셔야 할 것은 아테나는 이런 소스파일들을 다른 위치로 복사를 하지 않는 다는 것입니다. 모든 쿼리들은 원본 데이터를 대상으로 실행됩니다.
Step 2: Data Format
이번에는 꽤나 직관적인 단계입니다. 그냥 데이터 소스의 파일 포맷을 선택하시면 됩니다. 우리는 CSV파일을 예제로 사용할 것이므로 그것을 선택하시면 됩니다.
Step 3: Columns

세번째 단계로는 우리의 데이터 셋에 대하여 각 문서/레코드의 컬림/필드를 정의합니다. 이것은 아테나가 우리가 작업할 데이터의 스키마를 알 수 있게 해주므로 꼭 필요합니다. 여기서 정의되지 않거나 이름이 설정되지 않은 것은 값이 무시될 것입니다. 그래서 적절하게 컬럼을 설정하는 것이 중요합니다. 우리의 테스트 케이스에는 컬럼이 너무 많기 때문에 각각을 개별적으로 설정하는 것은 너무나 귀찮을겁니다. 그래서 벌크로 추가할 수 있습니다. 아래의 페이지에 벌크 옵션이 있으며 아래와 같이 설정할 수 있습니다.
_id string, string1, string, string2 string, double1 double, double2 double2
보시다 싶이 포맷이 꽤나 간단합니다. 컬럼의 이름을 정하고 한칸 띄우고 데이터의 타입을 적으면 됩니다. 컬럼 구분자는 콤마입니다.
Step 4: Patitions
이 과정은 파티션을 다루기 때문에 쪼끔 어려울 수도 있습니다. 우리의 데이터가 작기 때문에 여기서 다루기에는 부적절합니다. 그래서 이 단계를 스킵하고 다른 설정을 하도록 합시다.
여러분의 아테나 쿼리 설정이 끝났습니다. 쿼리페이지를 얻게 될 것이고 여기서 CREATE TABLE 쿼리를 이용해서 우리가 막 설정한 테이블을 만들 수 있습니다. 아까 테이블을 미리 만들었기 때문에 이 쿼리를 직접 치실 필요는 없습니다. 그냥 단지 참고용으로 알려드리는 거니까요. 아마 다음번에 설정하실 때는 콘솔에서 쿼리를 사용해서 수동으로 하실 수 있습니다.
우리에게 남은 것은 테이블에 쿼리를 날려서 설정이 적절한지 확인하는 것입니다. 먼저 다음과 같은 간단한 SQL 쿼리를 날려봅시다.
select * from sampledata limit 10;
이 쿼리를 실행하면 다음과 같은 화면을 보실 수 있습니다.

꽤나 긴 여정이었지만 이제 여러분은 아테나를 사용해서 S3에 있는 파일 기반의 데이터에 쿼리를 날릴 수 있게되었습니다. S3에 저장된 여러개의 파일들을 분석할 필요가 있을 때 매우 편리하실 겁니다. 여러분의 파일 포맷과 분사되어있는 파일에 따라서 쿼리의 성능은 달라질 것입니다.
Summary
- 아테나를 이용하면 AWS S3의 데이터에 쿼리를 날릴 수 있다.
- 그냥 설정만 간단히 하고 테이블을 설정하면 바로 쿼리를 날릴 수 있다.
- S3에 데이터를 분석할 경우 다른 곳으로 데이터를 옮기고 자시고 할 필요없이 그냥 아테나 설정하면 바로 쿼리를 날릴 수 있다. 매우 간편!